
An actually runnable (March 2023) tutorial for getting started with gymnasium and reinforcement learning
Complaints from an SRE trying to learn RL. PIN YOUR DEPENDENCIES

Every time I’m told to pip install something, but the tutorial is from 4 years ago and there’s no version information, I know it’s going to be a bad time. If you read this entire post, you’ll learn all the things I’ve learned so far with trying to get into reinforcement learning as an ML fan boy but a career infra and operations engineer. Also, buckle up, this is a thick post. This first post should probably be multiple posts but nah. I’m going to write what I know now.
Motivation
The motivation for all this work comes from a few places. First of all, I’ve always been super interested in machine learning. People who know me know that I’ve been experimenting with machine learning for many many years. But I have another love. And that’s Super Smash Bros Melee. Mang0 is the GOAT. More on this in a moment. A few weeks ago, I watched the AlphaGo documentary, where DeepMind did what was thought to be impossible, and they trained an AI that beat the long time world Go champion. DeepMind has done a lot of amazing projects, and a lot of their success has been from applications of reinforcement learning.
I’ve also been a casual chess fan. I have a 400 rating, am terrible at the game, but something about watching Levy “GothamChess” Rothman is very entertaining. A sentiment that chess players used to have, and that Go players in the documentary started to have, is to wonder if AI’s beating humans will mean that people will stop wanting to play the game. In fact, it’s been the opposite. AI has been found to be immensely useful in chess players being able to study the game. Just because a computer can calculate more moves ahead, humans are still fascinated in finding out how capable they can be given our limits.
Back to Melee. It’s the greatest game to have ever been created. It’s expressive, it’s fast, it’s beautiful. I love watching this game. I’m a bronze 2 shitter, but I still love watching this game. Let’s put this all together. I wondered to myself, is there a way that I can build a melee AI that will ultimately help push the meta forward? With the fearless exploratory capabilities that a reinforcement learning algorithm has, can we find new tech? If I trained a model for low tier characters, can we make them more relevant? I have no idea, but I’m interested in finding out.
Thus, I get started. This will not be the only thing I talk about in the coming weeks on this newsletter, but it might be a lot of the next few posts. Everything from previous RL work on Melee to scaling out model training, etc. I expect this project to be a running theme for a while but I’m too scatter brained to keep to a single long term project.
How do I get started with RL?
A few months ago, I read this article that says that OpenAI uses Ray.io. When I checked out the Ray documentation, I noticed that it has reinforcement learning capabilities. At the time, I took that information and stored it back in the brain archive room. Fast forward to when I’m interested in trying some RL work and I decided that Ray is where I want to get started. Ya’ll know that I’m an operations person. Ya’ll know that I run my own Kubernetes cluster. My assumption is that by the time I’m ready and capable of doing simulations in melee, that I’ll want to be able to distribute that work, and since Ray seems to be the hot shit here, I might as well start there.
So I start searching for tutorials and trying to follow them. And I notice something. None of these tutorials work. Either the tutorials aren’t for Ray, or I follow the steps and the provided code doesn’t run, or they don’t specify that you need a certain version of Python, etc. It’s maddening. I spent probably a full day and a half strictly trying just to get something running. I’m not an ML engineer, and the learning curve for getting started here feels way too hard, so I wanted to write about everything I learned.
Laying out the tools
Part of what made it really hard for me to get started was that there’s a set of standard terms and tools that all of these tutorials kind of just expect you to be familiar with. I was not, and I’m still not entirely sure I understand many of the specifics, but I wish someone had laid some of these things out for me when I was getting started.
I think of reinforcement learning as having 4 key components: Environment, Agent, Policy, Reward.
Environment - Often a simulation when training, but otherwise, the environment the world that is being observed and acting in. This can be a game, the real world, a description of a problem, etc.
Agent - This is the representation of the program. This might be the self driving car, this might be your character in a video game. An agent takes actions on an environment. In a fighting game, an agent has a move set to follow, and that’s all they can do on their own.
Policy - The policy is the algorithm or strategy for what an agent will do given a certain state of the environment. When you’re training a reinforcement learning model, you’re most likely to be referring to learning a new policy. When you play a fighting game, you are actually the policy.
Reward - There needs to be some kind of evaluation or feedback. The reward and cost model is going to dictate how the policy behaves.
When you put all of these 4 together, you have a policy that looks at the current environment, tells the agent to take an action, and the environment will change in some way which can give you a reward or punish you.
You’ll also have episodes / rollouts. These terms are mostly interchangeable from my understanding. Basically, this is one full simulation through an environment. So this could be a single chess match as one example.
“I see the Fox up-b’ing towards stage, I’m a Falco and I’m going to down air at the ledge to knock them into the blast zone. If it works, my reward is that they lose a stock”.
One of the first tools that you’ll see everywhere when you try to get started with reinforcement learning is OpenAI’s gym. Gym is a platform and set of abstractions for having a RL environment. It’s definitely become an RL staple and the standard way for everyone to integrate everything else. There are interfaces between gym and things like the Unity game engine, game console emulators, and more. Here’s the catch, OpenAI gym has actually ceased development. Gym has been locked in place and now all development is done under the Farama Foundation’s Gymnasium repository. Gymnasium does its best to maintain backwards compatibility with the gym API, but if you’ve ever worked on a software project long enough, you know that dependencies get really complicated. Ray is a modern ML framework and later versions integrate with gymnasium well, but tutorials were written expecting gym.
Okay, so that’s a quick overview of gym and gymnasium. What else are we using? Ray! So what’s up with Ray? Ray is a combination distributed workflow system with overlap with projects like Apache Spark, or Dask, but with some additional features and focus on machine learning workloads. The Ray ecosystem itself integrates deeply with many other libraries, but something that makes their documentation a little confusing to a total newbie, is that Ray loves its own ecosystem. What does that mean? Ray documentation and examples take every opportunity to use other parts of the Ray ecosystem. Examples might show you how to do something with Ray’s RLLib, but then will also give you examples using RayTune and RayServe, etc. Overall, I think this is awesome, but very confusing when you’re still learning all of the boundaries and what they do.
RayTune is a library for doing parameter grid searches and optimizations. In other words, it helps you find optimal hyper parameters for your model. Conceptually, think about it as a library to help you run more experiments. RayServe will help you turn your models into a REST API so that you can send requests to your model from other services.
Lastly, I’ll make a quick call out to other ML frameworks. Ray integrates with both tensorflow1, tensorflow2, and torch. Again, if you’re an ML engineer, you’re probably comfortable with these, but when you’re just an admirer/fanboy, it’s hard to keep up with all of these data science/ml libraries. Simply put, these libraries make it easier to architect neural networks, and since Ray supports both, you’ll find examples that use both but that can cause even more confusion with dependency management. Numerical computing libraries are incredibly finicky with their own dependencies, and if you try to install both tensorflow and torch like the Ray tutorial tells you to, you’ll likely end up with a conflict of versions of shared dependencies that both libraries use.
It’s awesome that Ray wants to demonstrate compatibility with both, but man did that make things confusing.
Making a code sample reproducible
If you type pip install ray which is so common in documentation or tutorials, you’ll possibly install the latest version, or maybe you followed a tutorial 6 months ago and pip will just report that it’s already installed with whatever version you had. You could force a new version with the -U flag but that doesn’t really solve the problem. You have multiple dependencies that are going to be installed and just installing “ray” isn’t going to do anything deterministic or predictable for you.
Let’s scope in what model we want to train to something very specific. I’m going to help you run this code which we want to save as main.py:
import gymnasium as gym
from ray.rllib.algorithms.dqn import DQNConfig
algo = DQNConfig().environment("LunarLander-v2").build()
for i in range(10):
result = algo.train()
print("Iteration:", i)
print("Episode reward max:", result["episode_reward_max"])
print("Episode reward min:", result["episode_reward_min"])
print("Episode reward mean:", result["episode_reward_mean"])
print()
env = gym.make("LunarLander-v2", render_mode="human")
terminated = truncated = False
observations, info = env.reset()
while True:
env.render()
action = algo.compute_single_action(observations)
observations, reward, terminated, truncated, info = env.step(action)
if terminated or truncated:
observations, info = env.reset()That’s it. I’m going to write this big-ass post to help you run this. What does this do? There’s a classic reinforcement learning “hello world” type problem called the LunarLander.
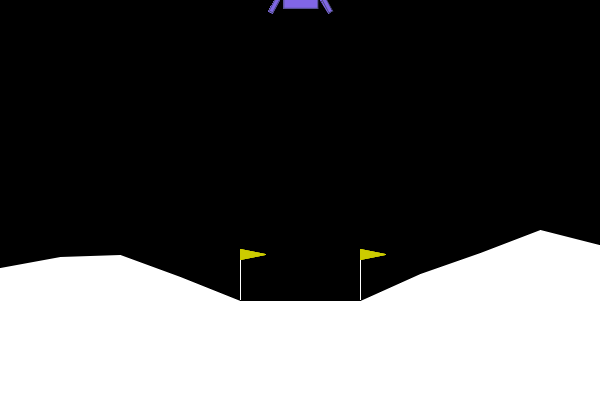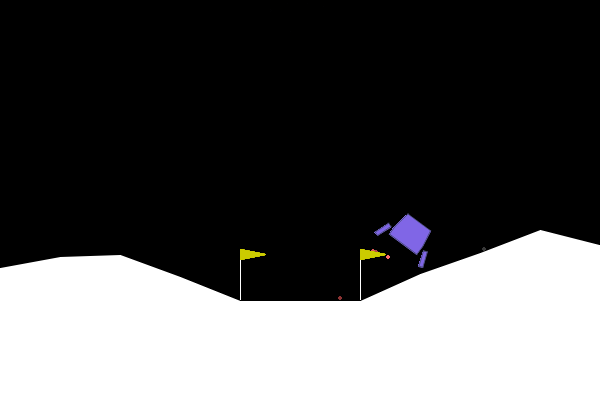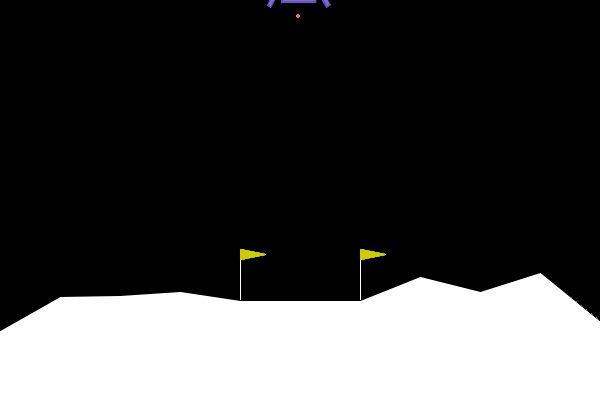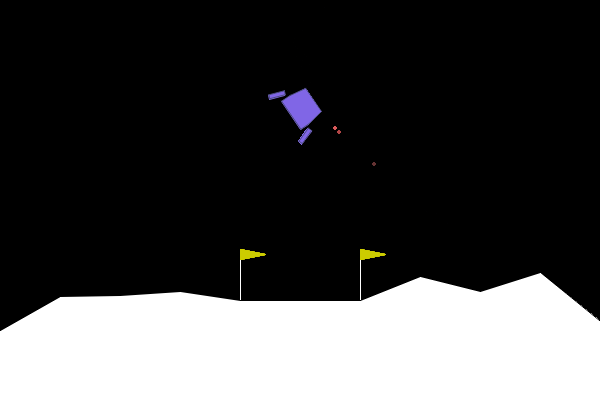
We run 10 training iterations where each training iteration runs the default number of episodes/rollouts. Then we have an infinite loop where we render and display the trained policy running on the LunarLander game. We’ll be digging into each section of code more deeply in the coming sections.
I just want to run it, Aaron!
Okay, okay, so what do you need to install it? I’ve generated the FULL dependency tree to run this example consistently using pip-tools. I am running everything with Python 3.8. I specifically use asdf-python for managing multiple versions of Python, but feel free to use pyenv. Once you’re running Python 3.8, save the following content to a file named requirements.txt:
#
# This file is autogenerated by pip-compile with Python 3.8
# by the following command:
#
# pip-compile --output-file=requirements.txt requirements.in
#
absl-py==1.4.0
# via
# tensorboard
# tensorflow
aiosignal==1.3.1
# via ray
astunparse==1.6.3
# via tensorflow
attrs==22.2.0
# via
# jsonschema
# ray
box2d-py==2.3.5
# via gymnasium
cachetools==5.3.0
# via google-auth
certifi==2022.12.7
# via requests
charset-normalizer==3.1.0
# via requests
click==8.1.3
# via
# ray
# typer
cloudpickle==2.2.1
# via
# gym
# gymnasium
contourpy==1.0.7
# via matplotlib
cycler==0.11.0
# via matplotlib
distlib==0.3.6
# via virtualenv
dm-tree==0.1.8
# via ray
farama-notifications==0.0.4
# via gymnasium
filelock==3.10.6
# via
# ray
# virtualenv
flatbuffers==23.3.3
# via tensorflow
fonttools==4.39.2
# via matplotlib
frozenlist==1.3.3
# via
# aiosignal
# ray
gast==0.4.0
# via tensorflow
google-auth==2.16.3
# via
# google-auth-oauthlib
# tensorboard
google-auth-oauthlib==0.4.6
# via tensorboard
google-pasta==0.2.0
# via tensorflow
grpcio==1.51.3
# via
# ray
# tensorboard
# tensorflow
gym==0.23.1
# via ray
gym-notices==0.0.8
# via gym
gymnasium[box2d]==0.28.1
# via -r requirements.in
h5py==3.8.0
# via tensorflow
idna==3.4
# via requests
imageio==2.26.1
# via scikit-image
importlib-metadata==6.1.0
# via
# gym
# gymnasium
# markdown
importlib-resources==5.12.0
# via
# jsonschema
# matplotlib
jax==0.4.6
# via tensorflow
jax-jumpy==1.0.0
# via gymnasium
jsonschema==4.17.3
# via ray
keras==2.12.0
# via tensorflow
kiwisolver==1.4.4
# via matplotlib
lazy-loader==0.2
# via scikit-image
libclang==16.0.0
# via tensorflow
lz4==4.3.2
# via ray
markdown==3.4.3
# via tensorboard
markdown-it-py==2.2.0
# via rich
markupsafe==2.1.2
# via werkzeug
matplotlib==3.7.1
# via ray
mdurl==0.1.2
# via markdown-it-py
msgpack==1.0.5
# via ray
networkx==3.0
# via scikit-image
numpy==1.23.5
# via
# contourpy
# gym
# gymnasium
# h5py
# imageio
# jax
# jax-jumpy
# matplotlib
# opt-einsum
# pandas
# pywavelets
# ray
# scikit-image
# scipy
# tensorboard
# tensorboardx
# tensorflow
# tifffile
oauthlib==3.2.2
# via requests-oauthlib
opt-einsum==3.3.0
# via
# jax
# tensorflow
packaging==23.0
# via
# matplotlib
# scikit-image
# tensorboardx
# tensorflow
pandas==1.5.3
# via ray
pillow==9.4.0
# via
# imageio
# matplotlib
# scikit-image
pkgutil-resolve-name==1.3.10
# via jsonschema
platformdirs==3.2.0
# via virtualenv
protobuf==3.20.3
# via
# ray
# tensorboard
# tensorboardx
# tensorflow
pyasn1==0.4.8
# via
# pyasn1-modules
# rsa
pyasn1-modules==0.2.8
# via google-auth
pygame==2.1.3
# via gymnasium
pygments==2.14.0
# via rich
pyparsing==3.0.9
# via matplotlib
pyrsistent==0.19.3
# via jsonschema
python-dateutil==2.8.2
# via
# matplotlib
# pandas
pytz==2023.2
# via pandas
pywavelets==1.4.1
# via scikit-image
pyyaml==6.0
# via ray
ray[rllib]==2.2.0
# via -r requirements.in
requests==2.28.2
# via
# ray
# requests-oauthlib
# tensorboard
requests-oauthlib==1.3.1
# via google-auth-oauthlib
rich==13.3.2
# via ray
rsa==4.9
# via google-auth
scikit-image==0.20.0
# via ray
scipy==1.9.1
# via
# jax
# ray
# scikit-image
six==1.16.0
# via
# astunparse
# google-auth
# google-pasta
# python-dateutil
# tensorflow
swig==4.1.1
# via gymnasium
tabulate==0.9.0
# via ray
tensorboard==2.12.0
# via tensorflow
tensorboard-data-server==0.7.0
# via tensorboard
tensorboard-plugin-wit==1.8.1
# via tensorboard
tensorboardx==2.6
# via ray
tensorflow==2.12.0
# via -r requirements.in
tensorflow-estimator==2.12.0
# via tensorflow
tensorflow-io-gcs-filesystem==0.31.0
# via tensorflow
termcolor==2.2.0
# via tensorflow
tifffile==2023.3.21
# via scikit-image
typer==0.7.0
# via ray
typing-extensions==4.5.0
# via
# gymnasium
# rich
# tensorflow
urllib3==1.26.15
# via requests
virtualenv==20.21.0
# via ray
werkzeug==2.2.3
# via tensorboard
wheel==0.40.0
# via
# astunparse
# tensorboard
wrapt==1.14.1
# via tensorflow
zipp==3.15.0
# via
# importlib-metadata
# importlib-resources
# The following packages are considered to be unsafe in a requirements file:
# setuptoolsThen to make sure that you’re not going to be having any other dependencies conflict with these, make sure to run in a new virtual environment. I’m not going to go into the details of virtual environments, there’s plenty of documentation about them. But basically after you save the above contents, just run.
python -m virtualenv venv
. venv/bin/activate
pip install -r requirements.txt
python main.pyThis will start the training loop. What were the high level dependencies that we installed? I generated that pinned version tree after installing the following dependencies:
ray[rllib]
gymnasium[box2d]
tensorflowWe install ray and the rllib extras, we install gymnasium for our environment and the box2d extras, and then tensorflow. So we install the general ML framework in tensorflow, we install the reinforcement learning framework in ray with rllib, and then we install the game environment with gymnasium and box2d. Box2d is going to be really valuable here because it installs pygame as a downstream dependency which will give us the actual game rendered on screen to visualize our trained algorithm which I think is at least half the fun. When you run the main.py, we’re currently only running 10 train loops which isn’t going to be enough to train a consistently functioning model, but you can change that number as you experiment.
Breaking down our code
The documentation for LunarLander on the Gymnasium website is actually amazing. I recommend just reading through that to understand all of what the environment actually entails. But in the context of our training loop, I want to emphasize one bit of text from the documentation.
An episode is considered a solution if it scores at least 200 points.
Q learning and Deep Q learning
So in our code, we start with:
algo = DQNConfig().environment("LunarLander-v2").build()So what is this doing? This creating an empty policy for a Deep Q Network, targeted towards the LunarLander environment. We just talked about the LunarLander, but we need to talk about Deep Q Networks and what this line of code is actually doing in the ray rllib library.
Q learning is one of the many many many reinforcement learning algorithms. I’m fucking AWFUL at math, so I’m not even going to attempt to derive that or explain it. But Q learning is simply the idea that you have some function named Q, and it takes two parameters. It takes the current state of the observable environment, an action to take, and it will give you an estimation for what the reward will be. Pretty simple. So in a plain Q learning setup, you can imagine that at every step of the game, you check the return value of your Q function for every action, and you just pick the action with the best prediction. If you have a very small environment space to work through, you could imagine literally hard coding the inputs and outputs of your Q function. Imagine writing a function that adds two numbers. If you know that your inputs will only ever be 0 or 1, you could write a function like so:
def add(a, b):
if a == 0 and b == 0:
return 0
if a == 0 and b == 1:
return 1
if a == 1 and b == 0:
return 1
if a == 1 and b == 1:
return 2A Deep Q Network applies a neural network for trying to learn more generalized reward calculation given more complicated states. Any practical usage of reinforcement learning is going to have way more nuances to how you calculate your output, but the basics of Q learning come from a very easy to understand concept. It makes for a great starting algorithm for a noob like me.
That being said, DeepMind was able to train a single model that could play most if not every Atari games using a Deep Q Network. So it’s also an incredibly powerful algorithm when used by people who know what they’re doing.
Training your model and counting your rewards
The line of code that I have is as simple as it can get. You can actually pass in all kinds of additional configuration here for Ray to understand how to distribute the work of this algorithm. The DQNConfig is where you’d configure things like GPU allocations, number of episodes in a single training iteration, etc. But I’m going to skip that for now because this post is already dummy thiqq.
for i in range(10):
result = algo.train()
print("Iteration:", i)
print("Episode reward max:", result["episode_reward_max"])
print("Episode reward min:", result["episode_reward_min"])
print("Episode reward mean:", result["episode_reward_mean"])
print()The next chunk of our code here is to do our training. A single call to train() will actually trigger thousands of simulations by default, then will report some statistics. Notably, we’re going to print out the episode reward. We noted earlier that a success for LunarLander takes a reward of 200. If you run this for 10 iterations, you’ll probably only see negative reward values here. In my experience, if you run with 30-50 iterations, you’ll at least see a reward max of 150-200, but that reward mean is going to stay negative. After a few hundred train loops, you’ll see a mean of over 200 but you might still have the occasional rollout with a large negative number.
Watching your algorithm go to work
env = gym.make("LunarLander-v2", render_mode="human")
terminated = truncated = False
observations, info = env.reset()
while True:
env.render()
action = algo.compute_single_action(observations)
observations, reward, terminated, truncated, info = env.step(action)
if terminated or truncated:
observations, info = env.reset()The last section of code is here to let us visualize how our algorithm is doing. The first line here is instantiating an entirely new gym environment for the LunarLander game, and setting the render_mode to “human”. Render modes were another thing that were really confusing to me because there’s convention about it but you’ll finds all kinds of documentation for custom render modes. Basically, the render_mode controls how the environment will… well, be rendered. The convention is that setting the render_mode to “human” will do whatever the environment needs for being viewable by human eye balls. In the case of LunarLander, that’s to render a pygame window to draw the game. By default, the environments won’t actually render anything because that takes more time and more compute. If you’re rendering a non-trivial video game environment, the game is almost guaranteed to run at 60 frames per second, which would mean 60 Q function steps per second. A game might take minutes to complete a full rollout, so this would slow down the training process by a lot. If the game can be run “headless” or purely computationally for simulation purposes, then using that headless render mode would make more sense for being able to do thousands or millions of simulations. Render modes might also attach to real physical devices when people are trying to do some experimenting, which is probably why the argument is just any arbitrary string. I would find so many tutorials that would show me a video of the results of the tutorial, but the tutorial itself NEVER explained render mode which made me think that I copy pasted something wrong or that my system was setup with the wrong dependencies, because I’d never actually see the game.
We create the environment, then we setup some defaults for variables that we’re going to use. Then comes the best part, running the game in a loop. First we call env.render() which is what updates the pygame window. Some RL environments might even just print to your terminal when you call render, but that render_mode being set to “human” has our back here. Next, we pass in the observable states to our trained policy, and it’ll return one of the defined actions according to the environment. Next, apply the action from the policy to the environment which will impact our space craft agent by having it trigger one of its thrusters. Lastly, we check to see if we’ve terminated or truncated our environment. To terminate or truncate the environment usually means something like we crashed, died on the level, or have been running for too long with no progress and got stuck. It’s up to the environment to define these states. Termination can actually also mean that we’ve beaten or won the level. If we hit either case, reset the environment back to the beginning of the level and just keep it going. If you’ve ran enough iterations of the training loop, hopefully that means you get an endless loop of the space craft landing safely between the flags. If not, you might be watching the space craft fly off the side of the screen or plummet to its death over and over again. Remember that these visualizations are not doing anything to update the model. This is purely to visualize the results of the training that has already happened.
Conclusion
Yeah, this post was a chunky boi. But I’m learning a lot with this project and writing this up is exactly the point of this newsletter. Checking my own understanding and trying to make this understandable is fun. It’s flexing a muscle that I should flex more often. Anyways, moving forward from this, I’m going to attempt to understand some more reinforcement learning algorithms. Q learning and DQN is great for starting, but I’m not sure if it’ll be enough to learn melee. Maybe it will be, who knows. At some point, I also need to learn more about what it’ll take to get melee available as a Ray compatible (aka gymnasium compatible) environment so that I can start doing simulations. There’s some previous work about using reinforcement learning with melee but thanks to the melee community, the tech around running melee has never been more advanced. Some of the previous work might apply, some might now. We’ll find out and when I do, you’ll hear about it.
See ya’ll in the next one.
where is the fucking code, whats wrong with your guys, same as documentation, where is the runnable code? we developer are not leisure as you guys.